合規披露與法律文件 Fyexa Capital 致力於提供透明、安全的交易環境。我們嚴格遵守安儒昂離岸金融管理 […]
Fyexa Capital 交易账户类型 Fyexa Capital 提供两种主流账户类型:标准账户适合新手和 […]
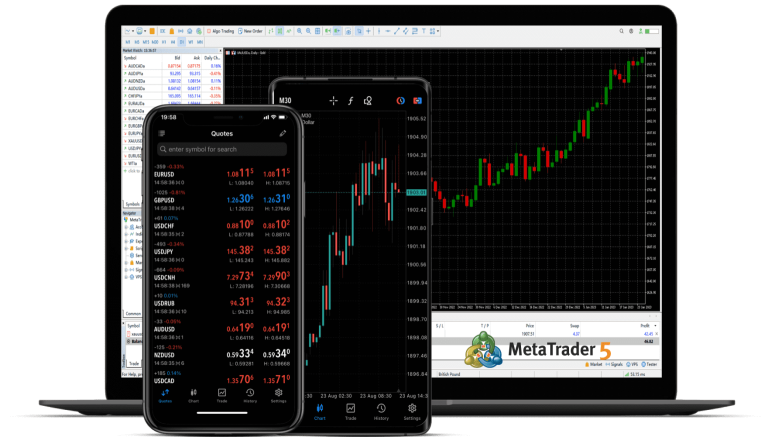
MetaTrader 5 (MT5):Fyexa Capital 的智能交易核心平台 MetaTrader 5 […]